MapReduce是一个编程模型,用于大规模数据集(大于1TB)的并行运算。用户首先创建一个Map函数处理一个基于 key/value pair的数据集合,输出中间的基于key/value pair的数据集合;然后再创建一个Reduce函数用来合并所有的具有相同中间key值的中间value值
1.定义
把Map和Reduce分开,它实现的主要思想也是依赖于Map(映射)和Reduce(归约)。
Map函数是一个处理key/value键值对的数据集合的过程,Reduce函数则是一个合并的过程。
- Map其实就是一个映射函数,可以当作JAVA中的HashMap的实现原理那样理解,因为它们都是以键值对(key and value)的形式存储和处理数据。
- Reduce(归约)合并所有具有相同key值的value值(也就是合并重复数据的过程)
2.实现原理:
一台计算机作为客户端(Master)向多台服务端计算机(Slave)发送命令,多台服务器计算机执行该任务然后返回结果给客户端。就是一个主仆模式,也就是一种分而治之的思想。 boss把工作分配给N个worker,每个worker获得一个任务,然后他们都做完之后都交给boss,boss只要合并一下。
3.实现过程
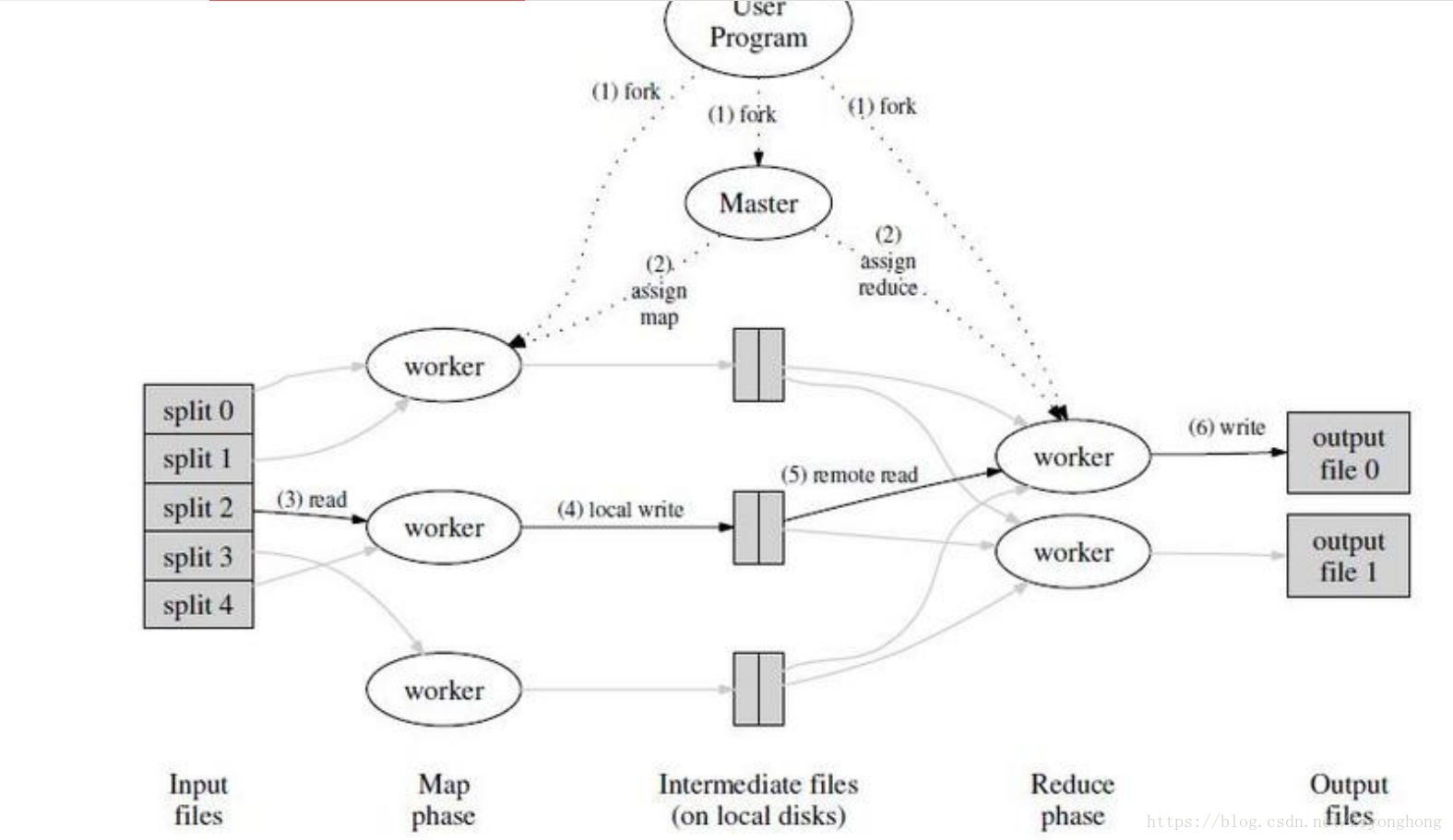
- 数据文件在加载时拆分成块(默认128MB)并进行分布,而且每个块被复制到多个数据节点中(默认3份)。
- Master将任务(被分成M个Map任务和R个Reduce任务)分配给空闲的worker
- worker读取相关的输入数据片段,数据片段会被解析成键值对。然后做Map函数(用户自定义的)处理。
- 通过图中的local write过程键值对被写入到本地磁盘上。(键值对是通过分区函数分成R个区域,再周期性的写入到本地磁盘的。)
- Master将数据存储位置(这个本地磁盘上的存储位置是由上一步返回的)发送给worker,worker读取数据。
- 对上一步的数据做Reduce函数(用户自定义的)处理。
4. 应用
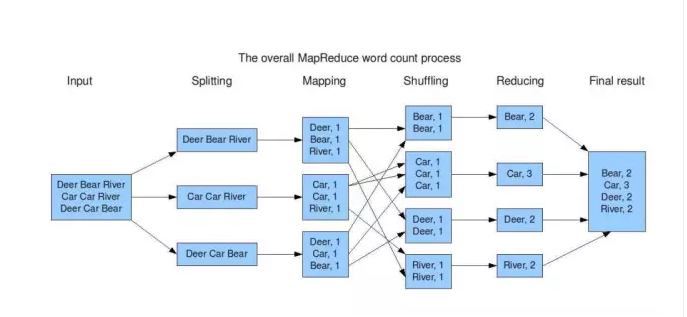 词频统计
词频统计
- 将输入的文件分割成块
- 执行map任务,将数据解析称键值对
- 不同机器根据键值对的key进行转移
- 执行reduce,将具有相同key的键值对规约
- 输出结果